
项目地址: diana
造轮子的意义
为啥已经有如此多的前端工具类库还要自己造轮子呢?个人认为有以下几个观点吧:
- 定制性强,能根据自己的需求为主导延伸开发。万一一不小心还能帮到别人(比如 React 库);
- 纸上得来终觉浅,很多流行的库,只是照着它们的 API 进行使用,其实这些库里蕴含着大量的知识、技巧,最好的办法就是仿照它们来写些小 demo,从而体会这些库的精髓;
- 造轮子的过程中能让自己体会到与平常业务开发不一样的乐趣;比如和日常业务开发中很大的一个区别是会对测试用例具有比较严格的要求;而且写文档能力提升了。
- 就先瞎编到这里了。。。
抛开内部方法(写相应的专题效果可能会更好,所以这里先略过),下面分享一些开发 diana 库 时的一些心得:
项目目录结构
1 | ├── LICENSE 开源协议 |
目录结构也随着方法的增多在不停迭代当中,建议直接到库中查看最新的目录结构。
相应地,具体的方法会随着时间迭代,所以首先推荐查看文档,点击如下图的 Ⓢ 就能查看源码。
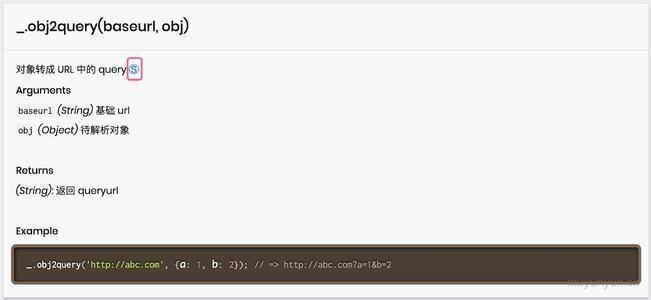
让模块同时在 Node.js 与浏览器中运行
我们可以通过如下方法来判断模块当前是运行在 Node.js 还是浏览器中,然后使用不同的方式实现我们的功能。
1 | // Only Node.JS has a process variable that is of [[Class]] process |
但如果用户使用了模块打包工具,这样做会导致 Node.js 与浏览器的实现方式都会被包含在最终的输出文件中。针对这个问题,开源社区提出了在 package.json 中添加 browser 字段的提议,目前 webpack 和 rollup 都已经支持这个字段了。
给 browser 字段提供一个文件路径作为在浏览器端使用时的模块入口,但需要注意的是,打包工具会优先使用 browser 字段指定的文件路径作为模块入口,所以你的 main 字段 和 module 字段会被忽略,但是这会导致打包工具不会优化你的代码。详细信息请参考这个问题。
在 diana 库 为了在不同环境中使用适当的文件,在 package.json 中进行了如下声明:
1 | "browser": "lib/diana.js", |
这样一来,在 node 环境中,引用的是 lib/diana.back.js 文件,在浏览器环境中,引用的是 lib/diana.js 文件。然后就能愉快地在浏览器端和 node 端愉快地使用自己特有的 api 了。
常见模块规范比较
另外为了使 diana 库 的打包文件兼容 node 端、以及浏览器端的引用,选择了 UMD 规范进行打包,那么为什么要选择 UMD 规范呢?让我们看下以下几种规范之间的异同:
CommonJS
CommonJs 是服务器端模块的规范,
Node.js 采用了这个规范。这些规范涵盖了模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套接字、单元测试、服务器网关接口、包管理等。根据 CommonJS 规范,一个单独的文件就是一个模块。加载模块使用
require方法,该方法读取一个文件并执行,最后返回文件内部的exports对象。CommonJS 加载模块是同步的。像 Node.js 主要用于服务器的编程,加载的模块文件一般都已经存在本地硬盘,所以加载起来比较快,不用考虑异步加载的方式,所以 CommonJS 规范比较适用。但如果是浏览器环境,要从服务器加载模块,这是就必须采用异步模式。所以就有了 AMD、CMD 解决方案。
AMD、CMD
AMD 是 RequireJS 在推广过程中对模块定义的规范化产物。AMD 推崇提前执行。
1
2
3
4
5
6// AMD 默认推荐的是
define(['./a', './b'], function(a, b) {
a.doSomething()
b.doSomething()
...
})CMD 是 SeaJS 在推广过程中对模块定义的规范化产物。CMD 推崇依赖就近。
1
2
3
4
5
6
7
8// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
...
})
UMD
UMD 是 AMD 和 CommonJS 的结合。因为 AMD 是以浏览器为出发点的异步加载模块,CommonJS 是以服务器为出发点的同步加载模块,所以人们想出了另一个更通用的模式 UMD,来解决跨平台的问题。
diana 库 选择了以 umd 方式进行输出,来看下 UMD 做了啥:
1 | (function (root, factory) { |
测试踩坑之路
代码覆盖率
单元测试的代码覆盖率统计,是衡量测试用例好坏的一个的方法。但凡是线上用的库,基本上都少不了高质量的代码覆盖率的检测。如下图为 diana 库的测试覆盖率展示。
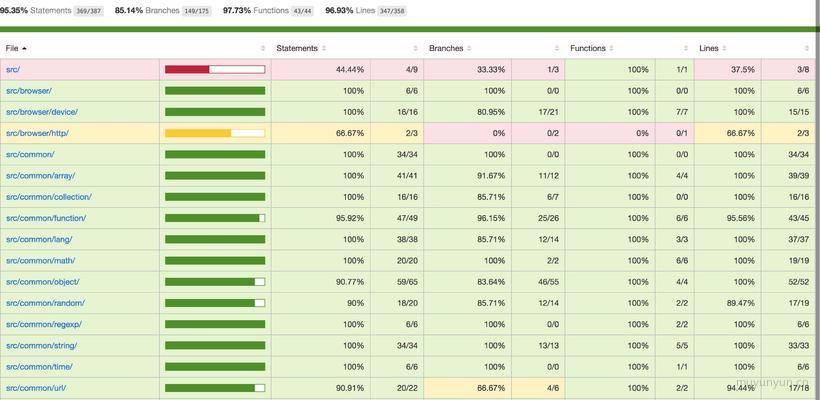
可以看到覆盖率分为以下 4 种类型,
- 行覆盖率(line coverage):是否每一行都执行了?
- 函数覆盖率(function coverage):是否每个函数都调用了?
- 分支覆盖率(branch coverage):是否每个if代码块都执行了?
- 语句覆盖率(statement coverage):是否每个语句都执行了?
番外:github 上显示的覆盖率是根据行覆盖率来展示的。![]()
mocha + istanbul
最初的版本, 仅仅用到 mocha 进行测试 *.test.js 文件,然后在 codecov 得到测试覆盖率。
引人 karma
如果仅仅测试 es5、es6 的语法,其实用 mocha 就已经够用了,但是涉及到测试 Dom 操作的语法等就必须建立一个浏览器,在上面进行测试。karma 的作用其实就是自动帮我们建立一个测试用的浏览器环境。
为了让浏览器支持 Common.js 规范,中间用了 karma + browserify,尽管测试用例都跑通了,但是最后的代码覆盖率的文件里只有各个方法的引用路径。最后只能又回到 karma + webpack 来,这里又踩到一个坑,打包编译JS代码覆盖率问题,踩了一些坑后,终于实现了可以查看编译前代码的覆盖率。图如下:
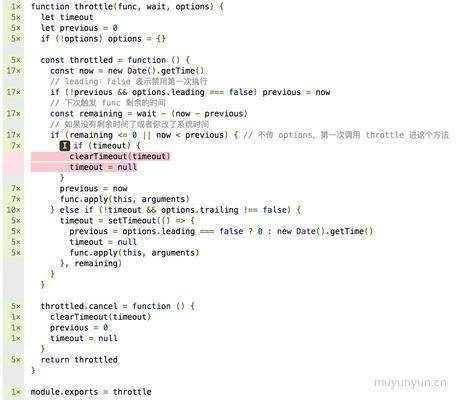
通过这幅图我们能清晰地看到源代码中测试用例跑过各行代码的次数(左侧的数字),以及测试用例没有覆盖到的代码(图中红色所示)。然后我们就能改善相应的测试用例从而提高测试覆盖率。
配置文件,核心部分如下:
1 | module.exports = function(config) { |
总结
本文围绕 diana 库 对造轮子的意义,模块兼容性,测试用例进行了思考总结。后续会对该库流程自动化以及性能上做些分享。
该库参考学习了很多优秀的库,感谢 underscore、outils、ec-do、30-seconds-of-code 等库对我的帮助。
最后欢迎各位大佬在 issues 尽情吐槽。