
插件地址(集成Github、掘金、知乎、淘宝等搜索)
作为 Mac 上常年位居神器榜第一位的软件来说,Alfred 给我们带来的便利是不言而喻的,其中 workflow(工作流) 功不可没,在它上面可以轻松地查找任何 api;可以快速在豆瓣上搜到自己喜欢的电影、图书、音乐;可以快速把图片上传到图床 等等。
一些安利
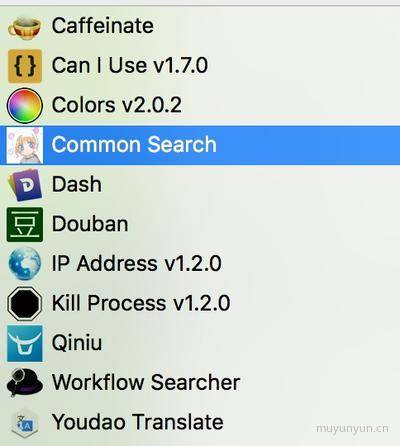
附上一张个人装着的插件的截图。Caffeinate 插件能在指定时间使电脑不黑屏;在 Dash 插件上能轻松查任何文档;Youdao Translate 插件比系统自带的翻译方便许多。插件也是因人而异,大家可以在 Workflow List 上逛逛,各取所需。
在用了别人的插件感觉高大上后,便萌发了也写一个插件的想法,计划把自己常逛的网站集合成一个插件,使用特定的缩略词便可快速进行搜索数据,又看了官方称可以使用 bash, zsh, PHP, Ruby, Python, Perl, Apple Script 开发 Alfred Workflow。于是我选择了 Node.js 作为开发语言,开发了一款 commonSearch, 开发完效果如下(集成了Github、掘金、知乎、淘宝等搜索)。

开发阶段
在开发前,得先对一些特定的操作步骤和知识点有一定的认知,这样开发时就基本上没有大碍了。
前置步骤
可以先参考 如何去写一个第三方的 workflow 的开始部分, 完成基本工作流的搭建,如下图是我搭建好的基本工作流连线。

在 Script 中,可以看到 /usr/local/bin/node common_search.js 相当于就是在调用该插件的时候起了一个 node 服务,后面的 1 是为了区分当前调用的是哪个搜索手动传入 common_search.js 的,{query} 则是用户查询的名称。
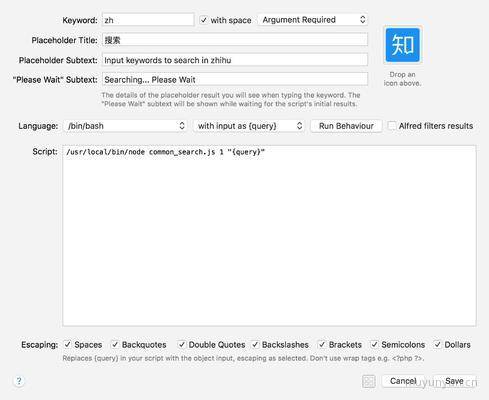
使用 Node.js 调用 JSON API
最初开发参考了 知乎搜索 这个项目,它是基于 cheerio 这个模块对请求到的网页数据进行分析爬取,但是引入了 cheerio 后,插件体积多了 2M 多,这对于一个插件来说太不友好了,所以这可能是 python 之类的语言更适合开发类似插件的原因吧(猜想:python 不需要引人第三方库就能进行爬虫),于是我开始选择提供 JSON API 的接口,比如找寻掘金返回数据的接口。首先打开 chrome 控制台,这可能对前端工程师比较熟悉了。
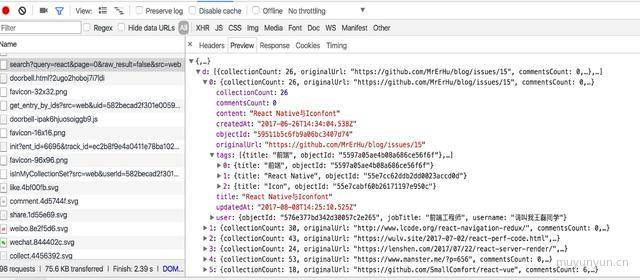
从而找到了掘金返回搜索数据的接口是 https://search-merger-ms.juejin.im/v1/search?query={query}&page=0&raw_result=false&src=web
接着愉快地使用 node 提供的 https 模块,这里有一个注意点,http.get() 回调中的 res 参数不是正文,而是 http.ClientResponse 对象,所以我们需要组装内容。
1 | var options = { |
这种方法应该是最直接的调用 JSON API 的方案了,当然也可以引人第三方模块 request 后解析 JSON,示例如下:
1 | var request = require('request') |
还有一点要注意的是返回值的字段是固定的,具体可以参考它的官方解释,琢磨了好久才把 JS 中的 Icon 自定义的格式找出来。
1 | title: 主标题 |
对于 Github、掘金、知乎、淘宝的搜索都是基于以上思路进行开发的,就是对于具体返回的 JSON 数据进行了不同处理,虽然粗糙,但也算完成了第一个 Alfred Workflow 插件的开发。
尾声
本文的知识点写的不是特别丰满,一是就是对开发这个插件的小结,另外就是抛砖引玉了,能让更多的小伙伴了解开发一个插件并不是难事,同时让更多的朋友开发出更多有意义,有趣的 alfred-workflow 插件也算是本文分享的一个初衷了。