Time is flying, it arrives at the end of year again. This is my first year working in PinDuoDuo inc and it seems I arrive in the company yesterday. This point is a good chance to talk with(recognize) myself again. I try to conclude from work, output, life and destination.
Learn from work
The first course I learn from my team is about starting with the end. It means everything we do today is prepared for the tomorrow. In the other word, we should realize which period the thing we’re doing is in, and our team write summary every week to make sure the established goals become closer and closer.
The second course I learn from the work is to try to use English more. There are so much rich resource in Medium, MDN, Frontend Masters and even in twitter. It’s the first time I met with so many foreigners engineer in the JSConf but I can’t talk with them fluently. It’s obviously using English skillfully will open your eyes and improve efficiency looking for some information.
The last but most important is how to communicate. It’s artistic to describe something easily to make others understand. When arriving at our team at first, one of my leader’s advice is the best way to join in the team is to share —— sharing ideas, knowledge and feeling. My colleagues are so excellent I learn a lot from them in these technical sharing parties every week. At the meanwhile I also share some ideas in it.
Output of the article
There are ten new articles added to my blog, the direction is to talk about React, JavaScript, CSS and so on. If there are mistakes in it, welcome point out.
- Introduction To Functional Programming
- Do Search In Data Structure Of React Fiber
- Understand React Suspense deeply
- You don’t know requestIdleCallback
- Deep into React Hooks
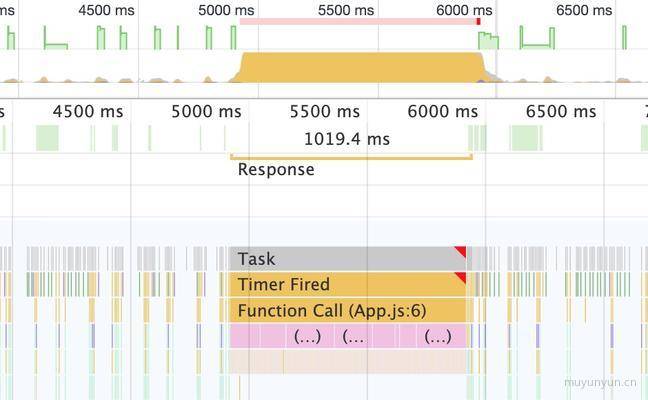
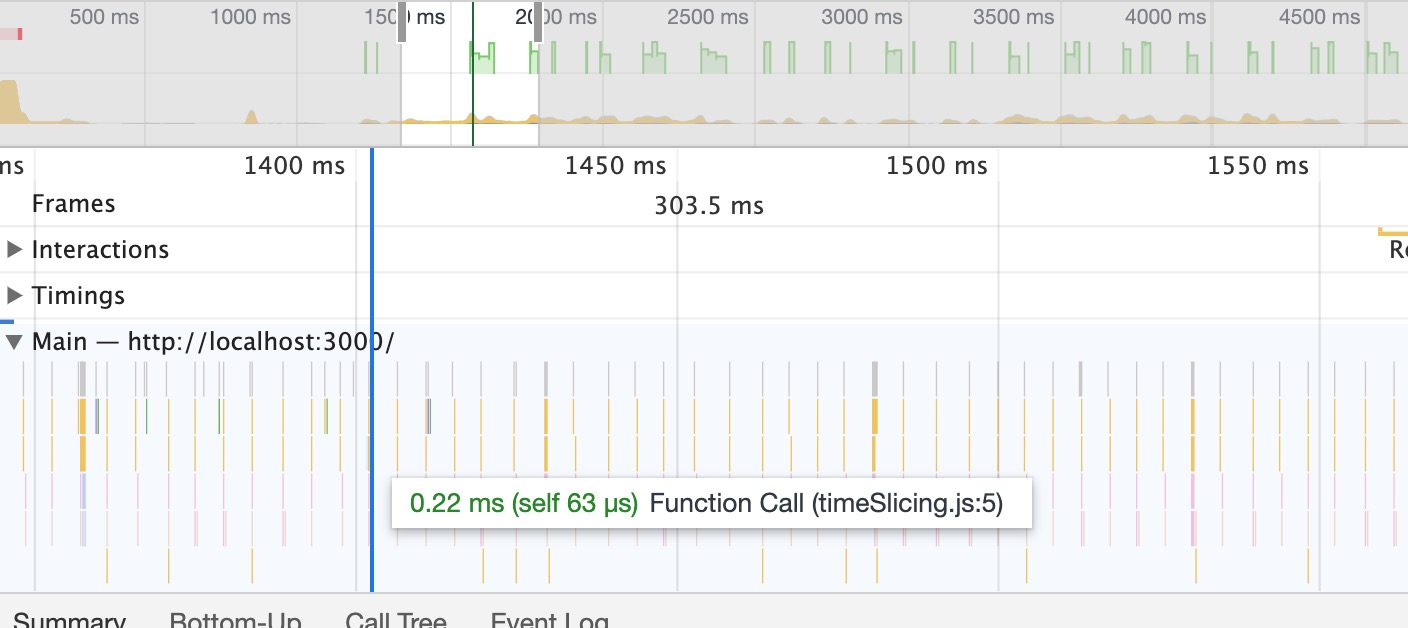
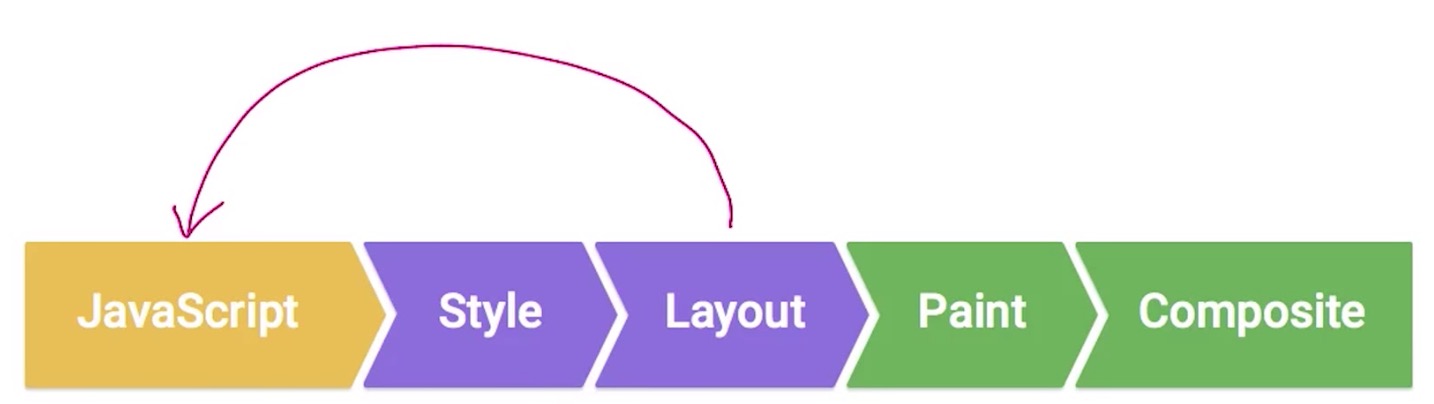
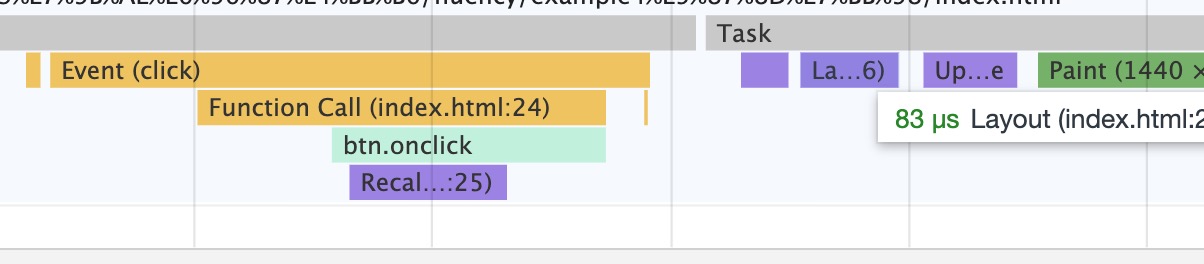
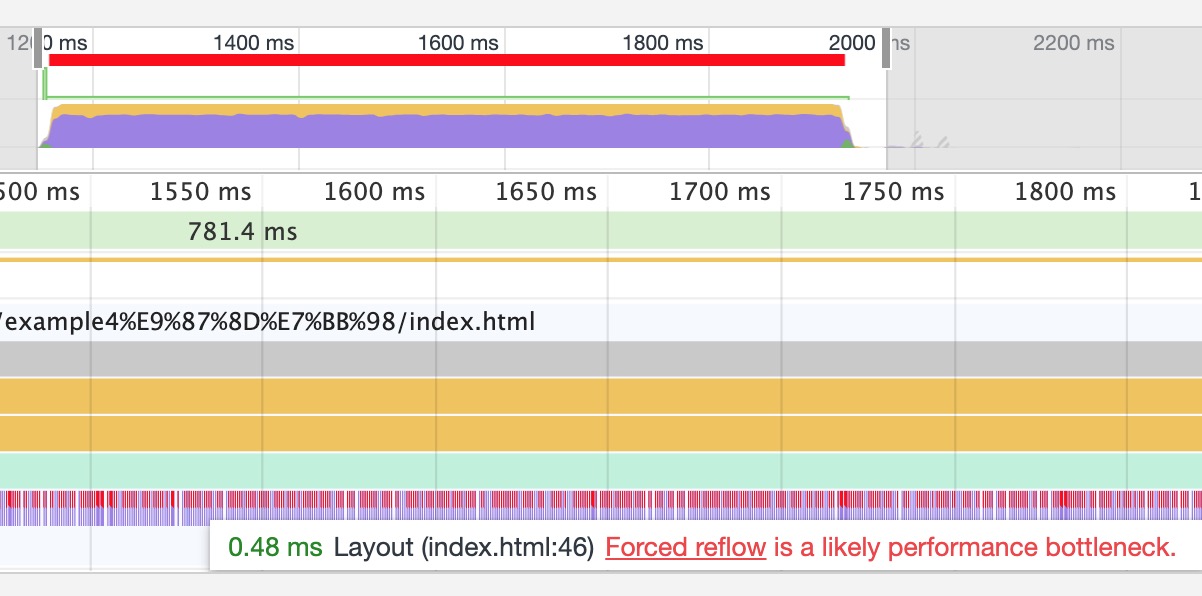
- How to make page run smoothly
- Deep into React Hooks —— Design Pattern
- Modern React test
- Learn Controlled Component and Uncontrolled Component Again
- INHERITED AND NON-INHERITED IN CSS
There will be more creative articles to add in the future. Let’s grow up together.
Life
I enjoy the quiet time sitting in the Cafe the whole day in Saturday and it’s also nice to chat with friends or family there.
And in other some weekend days, I take part in some FE conferences this year —— FDConf, VUE Conf, D2, SEE Conf and so on. From these activities I learn some some new knowledge. For example, the article How to make page run smoothly is written after listening the sharing of Liu Bowen in FDConf. And luckily, I get the chance to take photo with Evan You and get the
signature from him.

At the same time, it’s happy to meet with old friends and make with new friends in these activities.
Checklist && Destination
Checking the plan of last year before making plans in new year.
- Reading
fivetechnical books and a not technical book,learn Functional Programming: It is a shame not achieve this target. Instead of reading the whole books, I read more single posts or chapters partly in the last year. - Finishing
a valuable project: There are some valuable projects in my daily work, they’re still in progress. Deep into, submit a pr: There is some deep analyze in React this year, however it still needs making extra effort for making a pr;Reactcommunity- Deep
into the document of: the work of this year is connected with UI and component more closely, so the document of Node.Js has no much chance reading in practice;Node.Js Improving the skill of communication, do a sharing in a party: The communication skill gets some improved, however it still needs be strengthened;Invite friends fro coffee(at least 12)
Keeping going on in the new year. Here lists some direction.
- Keeping reading and writing. Creating more personal thoughts;
- Improving listening/writing skill in English continually;
- Way: watching ten+ english movies and try to write some english posts.
- Improving the basic skills in data structure and composition principle continually;